Implementing an LLM Agnostic Architecture for our Generative AI Module

Entrio was the first company in the asset management space to adopt generative AI as part of our application, infrastructure, and data collection pipelines. Over the past year, generative AI and LLMs (Large Language Models) have been rapidly evolving the landscape of products and features. Notably, the adoption of LLMs has become an indispensable asset for organizations seeking to leverage the power of natural language processing.
In order to explore the full potential of Generative AI and LLMs for our platform, we decided to develop an LLM Agnostic Architecture. This flexible, scalable solution combines several key components enabling us to enrich data, accelerate our operations, create a feature rich application, and mitigate vendor and feature lock-in.
Working with a single LLM provider can prove challenging, so the idea of managing multiple LLMs can be daunting. In this post, we’ll outline the structure, components, limitations, and benefits of an LLM Agnostic Architecture and how we’re leveraging it for our Generative AI Module.
Overview of the LLM Agnostic Architecture
The LLM Agnostic Architecture is a modular and extensible framework designed to facilitate the integration and management of multiple LLMs from various providers. At its core, this architecture decouples the application logic from the underlying LLM implementations, enabling us to seamlessly switch between different models or leverage multiple models concurrently. In addition, it decouples, as far as it can, the prompt engineering efforts and the Retrieval Augmented Generation (RAG) layer from the underlying LLM.
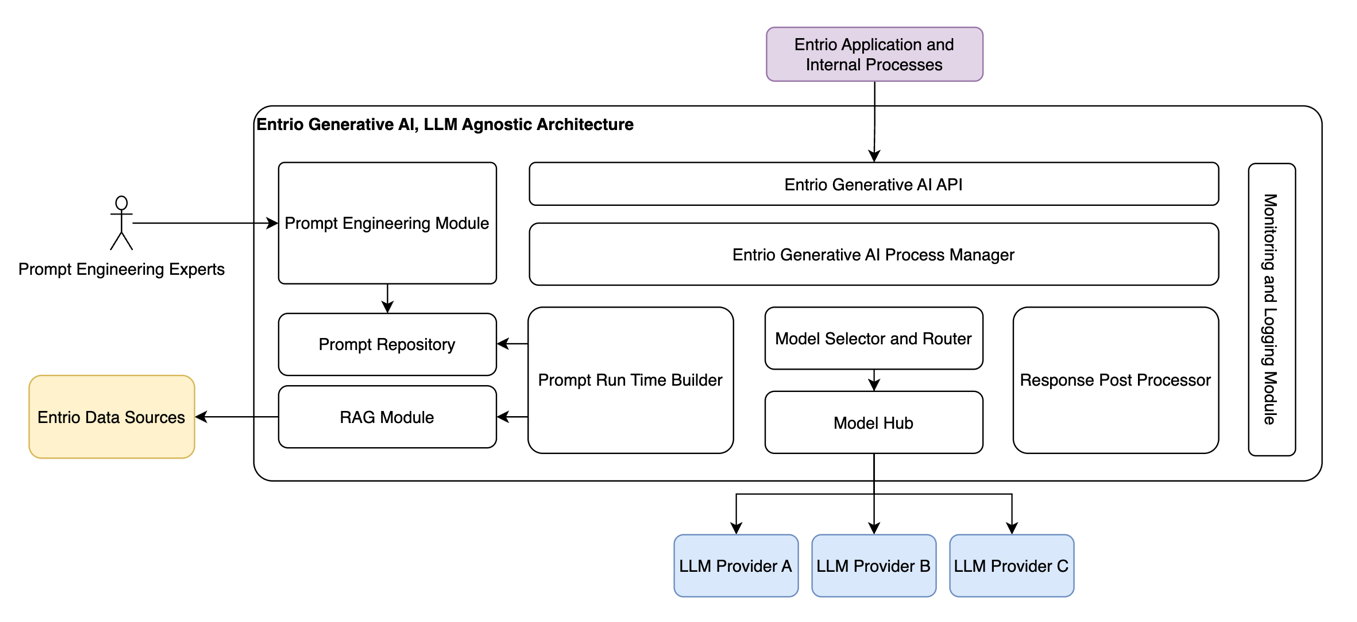
The architecture is made up of several key components, each playing a crucial role in ensuring efficient and effective LLM utilization:
1. Generative AI API – an Abstraction Layer
This layer acts as a unified interface, abstracting away the complexities of individual LLM implementations. It provides a standardized set of APIs that enable seamless communication between the application logic and the underlying LLMs, regardless of their origin or provider.
2. Generative AI Process Manager – the Orchestration Layer
The Generative AI Process Manager is responsible for orchestrating the operations needed to fulfill an API call. It encapsulates all the complexities of the process and activates all the modules to complete the steps needed to create a result.
3. Prompt Engineering Module & Prompt Run-time Builder
Recognizing the pivotal role of prompts in guiding LLMs, the Prompt Engineering Module focuses on crafting effective and context-aware prompts. It leverages techniques such as prompt tuning, prompt chaining, and prompt augmentation to enhance the quality and relevance of LLM outputs. Once prompts are approved for use, they are stored in a repository.he Prompt Run Time Builder retrieves the relevant prompt from the repository, enriches it with data from the RAG module, and injects the relevant run-time parameters. Once a prompt is built, it is sent by the Model Router to the Relevant LLM, through the Model Hub.
4. Retrieval Augmented Generation (RAG)
RAG is a powerful technique that combines the strengths of LLMs with information retrieval systems. By integrating external knowledge sources, such as databases or document repositories, RAG allows LLMs to leverage contextual information, resulting in more informed and accurate responses.
5. Model Router and Model Hub
The model router component acts as the brain of the architecture, determining the most suitable LLM or combination of LLMs for a given task. It considers factors such as model performance, cost, and task-specific requirements, enabling efficient resource utilization and optimized results. Upon decision, the router sends the prompt to the relevant model, via the model hub, which acts as a gateway to the model providers.
6. Response Post-Processor
LLM outputs often require further processing and refinement to ensure they meet the desired format, tone, and quality standards. The Response Post-Processor component handles this critical task, applying techniques such as output filtering, grammar and style correction, and content formatting to enhance the final output before presenting it to the end-user or downstream application.
7. Monitoring and Logging Module
Ensuring correctness, transparency, and accountability is crucial when working with LLMs. This component facilitates comprehensive monitoring and logging of internal module operations and LLM interactions. It tracks performance, detects potential bias, and keeps track of prompt engineering efforts, prompt evolutions, changes between results, costs, and process monitoring.
Challenges and Limitations of an LLM Agnostic Architecture
While the LLM Agnostic Architecture offers numerous benefits, it’s essential to acknowledge and address its inherent limitations and challenges. These are usually derived from the LLM world itself, but they are magnified when trying to establish LLM agnostic processes. Here are a few of the key ones to consider:
1. Prompt Engineering Complexity
Crafting effective prompts for LLMs is a complex and iterative process, requiring domain expertise, and a deep understanding of the model's capabilities and limitations. To overcome this challenge, we must invest in developing tools, methods, and practices to maximize the potential of generative AI. The challenges are not only in crafting effective prompts, but also being able to dynamically build appropriate prompts, in run time, with the relevant information needed – both from static and dynamic parameters and from the RAG module. The complexity should be also handled with code-control-like tools to handle history and versioning of the outcomes of the prompt engineering efforts.
2. Contextual Awareness and Real-World Knowledge
LLMs, by their very nature, lack the contextual awareness and grounding in real-world knowledge required for certain tasks. Integrating external knowledge sources through techniques like RAG can help mitigate this limitation, but it introduces additional complexities in data management and retrieval, as data should be accessible by the run time prompt builder dynamically.
3. Ethical Considerations and Bias Mitigation
As LLMs become more prevalent, concerns around ethical implications, such as potential biases and harmful outputs, must be addressed. The LLM Agnostic Architecture should incorporate robust monitoring and governance mechanisms to detect and mitigate these risks.
4. Stability, Scalability, and Performance Challenges
As LLMs are different in their capabilities, it is important to create a robust approach that can measure the stability of responses, to remain accurate over time. In addition, as the number of LLMs and data sources increases, we may face scalability and performance challenges. Careful architectural planning, load balancing, and caching strategies are necessary to ensure efficient and reliable operation at scale.
5. Continuous development and Model Introductions
LLMs and Generative AI models are part of an ever-changing landscape. Models are retried and introduced at a fast pace. Once models are retired, new models can change the reaction to specific prompts. This nature of the underlying landscape can be mitigated by using agile approaches in both architecture components development and in prompt engineering efforts.
To overcome these limitations, we must adopt a holistic approach that combines technical solutions with robust frameworks, continuous model evaluation and feature explorations, and ongoing optimization efforts, both on the module development and integrations and on the prompt engineering and development.
Exploring the Benefits of an LLM agnostic architecture
Implementing the LLM Agnostic Architecture offers numerous benefits that empower organizations to unlock the full potential of LLMs while future-proofing their investments.
1. Vendor Agnosticism and Flexibility
By decoupling the application logic from specific LLM implementations, we can easily switch between different LLM providers or leverage multiple models simultaneously. This flexibility fosters innovation, reduces vendor lock-in, and enables us to easily explore new LLMs as soon as they are introduced.
2. Scalability and Cost Optimization
The LLM Agnostic Architecture facilitates efficient resource utilization and cost optimization by enabling organizations to dynamically allocate and orchestrate LLM resources based on task requirements and performance metrics. This scalability ensures that organizations can adapt to changing workloads and evolving business needs.
3. Improved Accuracy and Contextual Awareness
By leveraging techniques like RAG and integrating organizational knowledge sources, the LLM Agnostic Architecture enhances the accuracy and contextual awareness of LLM outputs. Once it’s combined with the ability to choose a correct LLM for a specific task, it results in more informed and reliable responses, enabling us to deliver more accurate results, enrich more data points, enhance user experience, and make better-informed decisions.
4. Future Proofing and Innovation
By developing a modular and extensible architecture, we can future-proof our investments and remain agile in the face of rapid technological advancements. As new LLM models and techniques emerge, we will be able to integrate them almost seamlessly, enabling us to stay at the forefront of innovation with the newest generative AI models.
For Entrio, implementing the LLM Agnostic Architecture is a strategic investment that positions us for long-term success in the era of LLMs and generative AI. By implementing this architecture, we can go forward with feature rich offerings to our clients, and in parallel, explore and unlock the potential of generative AI, both for Entrio’s internal operations and as part of what we deliver to our customers.

